Importance sampling is a Monte Carlo method for evaluating properties of a particular distribution, while only having samples generated from a different distribution than the distribution of interest.
Suppose we want to compute the expectation of an arbitrary function \(f\) of a random variable \(Y\), which is distributed according to the distribution \(p\): \[ E_p[f(Y)] := \int f(y) p(y) dy\]
In case the integration becomes difficult, we can use a Monte Carlo method. \[ E^{MC} := \frac{1}{N} \sum_{i=1}^N f(y^{(i)})\] By the law of large numbers, this estimate will almost surely converge to the true value as the number \(N\) of particles (i.e., sampled values) increases.
Although this appears straightforward, sampling from the target distribution, \(p\) is not always possible or efficient. Importance sampling bypasses this difficulty by sampling particles from an arbitrary “instrumental distribution” \(q\) and weighting the particles by accounting for they were sampled from \(q\) but not from \(p\).
Importance sampling fundamental identity
\[ E_p[f(Y)] := \int \frac{f(y)}{q(y)} q(y) p(y) dy = E_q[w(Y) f(Y)]\] where we define the importance weight \(w(y) = \frac{p(y)}{q(y)}\)
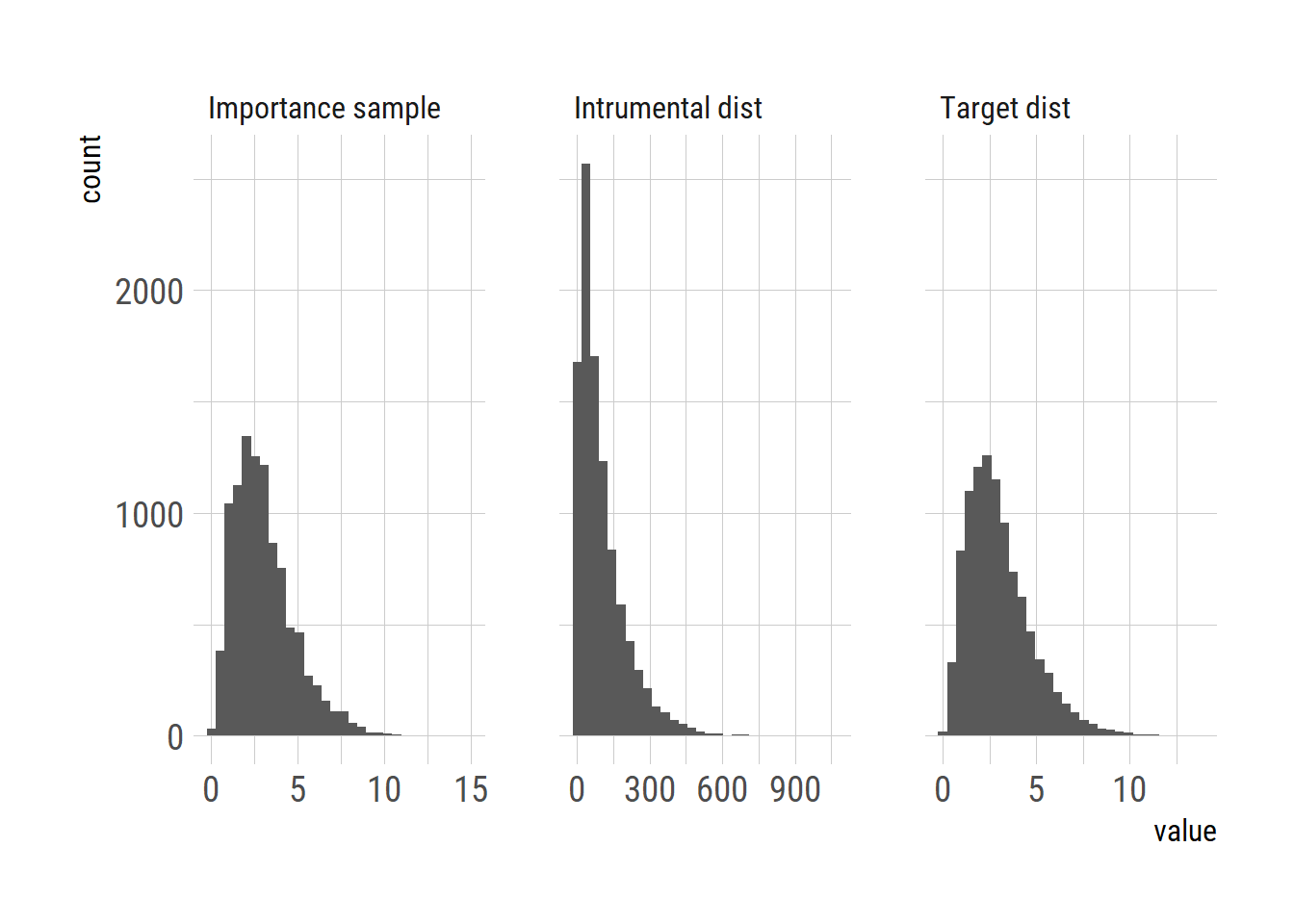
Let’s see an example in which we create Gamma-distributed sample from the exponentially distributed sample.